
Linux 流量控制实施指南
Version 1.0.2
作者:Martin A. Brown
翻译:greensea
© 2006, Martin A. Brown
您可以在GNU自由文档协议许可证1.1版(或更新版本)的许可范围内复制、发布或修改本文档,但不包含不可更改章节、封面及封底。GNU自由文档许可证可在这里查看:http://www.gnu.org/licenses/fdl.html。
© 2011, greensea
本文由 Martin A. Brown 的 Traffic Control HOWTO 翻译而来,并以 GFDL 协议发布。
2011年03月02日
摘要
要实施流量控制,我们需要一系列工具对网络接口上发送或接收到的数据包进行控制,把这些数据包按照一定的顺序进行发送或接收。这些控制操作包括排队、决策、分类、调度、整形和丢包。本指南将简要介绍流量控制的一些概念和实施方法。
目录
- 1. Linux流量控制介绍
- 2. Linux流量控制思想简介
- 3. 流量控制中的概念
- 4. Linux流量控制中的组件
- 5. 软件和工具
- 6. 非分类排队规则(非分类
qdisc) - 7. 分类排队规则(分类
qdisc) - 8. 约定和一些常见场景
- 9. 用于流量控制和 QoS 设置的脚本
- 10. 图表
- 11. 常用网站和资源
1. Linux流量控制介绍
Linux提供了一系列可用于修改和调整网络数据包的工具。Linux社区对修改数据包、应用防火墙策略(如netfilter或更古老的ipchains)以及在Linux上运行着的各种各样的网络服务已经非常熟悉。然而,Linux社区内部却很少有人知道Linux的流量控制子系统已经非常成熟,并且有着强大的功能。在Linux社区外,Linux流量控制的功能更是鲜有人知。
本指南将会介绍 流量控制的思想、 方法以及Linux流量控制的组件。同时会提供一些一般性的指导。 . 这份指南是笔者根据LARTC HOWTO、对各种软件项目的研究,以及在LARTC mailing list上的一些重要主题整理而成的。
对于急于实施Linux流量控制的人,建议直接阅读 Traffic Control using tcng and HTB HOWTO何LARTC HOWTO这两份资料。
1.1. 目标读者
这份指南的目标读者应该是那些想要了解Linux流量控制和实施细节的网络管理员或具有一定基础的家庭用户。
本指南的读者应该具有一定的Unix操作经验和基本的IP网络知识。如果读者想要实施流量控制,可能还需要具备给内核打补丁,编译和安装内核的能力。 [1]. For users with newer kernels (2.4.20+, see also 第 5.1 节 “内核版本要求”), however, the ability to install and use software may be all that is required. 如果用户使用的内核版本较高(2.4.20+,参考第 5.1 节 “内核版本要求”),用户就不需要具备编译安装内核的能力。
Broadly speaking, this HOWTO was written with a sophisticated user in mind, 虽然可能有些读者已经有过一些实施Linux流量控制的经验,但我还是假设大多数读者之前并没有实施Linux流量控制的经验。
1.2. 关于本手册
本文在vim下完成,并使用DocBook(version 4.2) 生成。行文样式由 xsltproc 根据 DocBook XSL 和 LDP XSL 样式表进行控制。生成的文件效果和大多数电子版技术文档相同。
1.3. 阅读建议
强烈建议入门用户先突击学习一下 tc,大致了解它的语法,最后再来重点关注 tcng。tcng 定义了一种全心的语法来描述流量控制结构,初看起来这种语法很难掌握,但熟练之后用户就能很轻松灵活地更改和应用流量控制结构,而且要比直接使用 tc 方便易懂许多。
当情况允许的时候,我会先描述流量控制系统的行为,同时给出用 tc 或 tcng 实现的例子。但我不会把 tc 和 tcng 的例子都列出来,读者应该能从一种例子中触类旁通知道如何使用另一种方法来完成流量控制。
1.4. 批评、建议以及内容补充
本手册还有不少没有完成的章节,包括下面的一些内容:
- 有关 GRED、WRR、PRIO 的介绍和图表。
- 有一些小节需要补充例子。
- 有关分类器的更具体的介绍。
- 一个专门讨论如何计算流量的小节。
- A section covering meters.
- More details on tcng. 有关 tcng 的更多介绍。
因笔者水平有限,文中难免存在错误和不妥之处,欢迎通过电子邮件发送您的意见、更正或者建议。另外,本手册近作为一份指导性的说明,读者在根据本手册的说明进行操作时务必要小心,笔者不承担根据本手册说明进行操作而造成的任何不良后果。
[1] 有关如何安装实施Linux流量控制所需软件包和内核的说明,请阅读第 5 节 “软件和工具”。
2. Linux流量控制思想简介
本节将会简要介绍 Linux流量控制并说明为什么要实施流量控制,同时指出实施流量控制的一些优点 和缺点,最后再介绍Linux流量控制思想中的关键要素。
2.1. 什么是流量控制
流量控制就是在路由器上通过一系列队列,对数据包进行排序以控制它们的发送顺序,并通过一系列策略控制收到的和发送的数据包是否应该被丢弃,同时还要对数据包的发送速率进行控制。
在大部分情况下,流量控制只有一个队列,接收收到的数据包(译者注:这里的接收到的数据包指的是由本机应用程序产生的数据包,而不是指从网络上接收到的数据包),把它们放入队列,并以网络硬件所能支持的最大速度发送出去。这种类型的队列叫做FIFO。
![]()
注意
Linux默认的排队规则是pfifo_fast,这是一种比FIFO稍微复杂一点的排队规则。
不同的应用有不同类型的队列。队列就是一种用于组织未能立即开始的任务或数据流的方法(参考???)。网络链路通常要求数据包以一定的顺序发送,因此我们需要在本机网络出口上使用队列来管理数据包。
如果一台桌面电脑和一台流量较大的网站服务器共用一条网络链路,那就有可能发生带宽争夺。由于网站服务器的上行流量很大,超过了链路速度,从而路由器上的队列被来自网站服务器的数据包挤满。路由上的队列被挤满后,路由器就会开始丢包,这会导致桌面电脑的丢包率上升,数据延时增大。过大的延时会让桌面用户抓狂的。如果我们把这条链路分成两部分,分别给桌面电脑和网站服务器使用,就能较好地分配带宽资源,让两者都能比较正常地工作。
在Linux下,用户可以通过一系列工具在网络端口上应用不同类型的队列和策略来实施流量控制。这些工具提供的功能都很强大,同时也很复杂。但是,虽然实施流量控制可以改善网络质量,但提高带宽所得到的效果总是优于实施流量控制的。
QoS(Quality of Service,服务质量)通常也被当做是一种实施流量控制的方法。
2.2. 为什么要实施流量控制
分组交换网络和电路交换网络的一个重要不同之处是,分组交换网络是无状态的,而电路交换网络是有状态的(如电话线路)。分组交换网络被设计成和IP网络一样,是无状态的网络,无状态属性保证了包交换网络的健壮性。
无状态网络的缺点是无法很好地区分网络上的数据流类型。而通过实施流量控制,我们可以根据数据包的类型来决定其发送的方法和顺序,这就可以在无状态网络上模拟出一个有状态网络。
流量控制还可以用于很多网络环境下。下面列出了一些例子,在这些情况下,实施流量控制通常可以解决问题,至少也能把糟糕的情况改善一些。
流量控制可用于很多情况,下面的例子并没有完全包括所有的情况。但列出这些例子可以帮助读者了解,在何种情况下实施流量控制可以收到不错的效果。
常见的流量控制实践
- 使用TBF和HTB把带宽限制在一个数值之下。
- 使用HTB和classifying,并配合使用
filter,限制某个用户、某个服务或某个程序所能使用的带宽。 - 在非对称线路(如ADSL)上最大化TCP协议的吞吐量。这可以通过提高ACK数据包的优先级来实现。
- 为某个用户或某个应用保留一定的带宽。这可以通过HTB和classifying来实现。
- 提高延时敏感性型用的性能。这要通过在HTB内使用PRIO来实现。
- 合理分配多余的带宽。可以通过HTB的租借机制来实现。
- 在无限制的网络上实现公平分配资源。这可以通过HTB的租借机制来实现。
- 丢弃某种类型的数据包。这可以通过
policer和filter来实现。
记住,在大多数情况下,购买更多的带宽会比实施流量控制取得更好的效果。实施流量控制并非长久之计。
2.3. 实施流量控制的好处
若能正确地实施流量控制,那就能让网络得到更充分地使用,减少网络上的竞争。大流量的下载不会破坏实时程序的交互性,同时也能让低优先级的数据传输(如电子邮件)正常进行。
更广义上,如果流量控制的策略能很好地符合与用户约定好的网络使用规则,那么用户也就能更合理地使用有限的网络资源。
2.4. 实施流量控制的缺点
复杂性是实施流量控制的一个主要缺点。虽然可以借助一系列工具的帮助来降低实施流量控制的复杂性,但是要想从已经配置好的流量控制方案中找出不恰当的配置也依旧不是一件容易的事情。
正确实施流量控制可以更公平地分配网络资源,但若配置不恰当,可能反而会恶化网络环境,使网络资源的分配更加不公平。
流量控制的规则越多,路由器就要使用更多的处理器资源来处理这些流量控制规则,我们要保证路由器有足够的能力来处理我们所设定的流量控制规则。幸运的是,路由器不需要消耗太多的计算资源就能处理比较复杂的规则。从另一方面来说,我们更应把注意力放在如何保证如此复杂的流量控制规则不会出现错误。
对于个人用户来说,实施流量控制几乎是零成本的。但对于企业来说,实施流量控制所付出的成本可能要比购买更大的带宽还要多,因为雇用一个了解流量控制的员工所需的工资可能比每月的带宽费用还要多。
Although traffic control on packet-switched networks covers a larger conceptual area, you can think of traffic control as a way to provide [some of] the statefulness of a circuit-based network to a packet-switched network.
2.5. 队列
队列是调度的实现。一个队列中会有有限多个对象,这些对象将在队列中排队等待以便被处理。在网络中,队列中的对象就是数据包,数据包在队列中排队等待网卡将它们发送出去。最简单的一种情况是,队列中的数据包按照先进先出规则进行排队,最先进入队列的数据包将会被最先传输出去,而最后进入队列的数据包将被最后传输出去。 [2]. 在计算机网络(或计算机科学)中,这种排队方式就叫做 FIFO.
如果不使用其他组件,单纯的队列无法提供流量控制的功能。队列只有两种操作,当数据包到来时执行入队操作,当有数据包可以发送时执行出队操作。
当队列配合其他组件使用时,就能实现很多的功能。我们可以同时使用多个队列,对数据包进行重排、丢弃、改变优先级等操作。
对运行在高层的应用来说,数据包只要能被发送出去就可以,至于发送顺序如何倒不是很重要。因此,对高层应用来说,流量控制系统就只是一条单一的队列。 [3] 只有对于流量控制本层来说,流量控制结构才是可见的和有意义的。
2.6. 数据流
一个数据流就是两台主机间建立的一条连接。任何经由这条连接发送的一系列数据包都可以看成这两台主机间的一条数据流。在TCP中,源IP和端口及目的IP和端口唯一决定了一条数据流。在UDP中也类似如此。
流量控制可以将网络流量分割成不同类型的数据流,这些数据流可以作为一个整体进行传输(参考DiffServ)。不同的流量控制结构可以将网络流量平均地分割成不同的数据流。
当网络中的数据流发生冲突时,对数据流进行处理就显得非常重要。这种情况常见于一个应用程序产生了大量的数据流时。
2.7. 令牌桶
在流量整形中,令牌桶算法是一种很常用的整形方法。
为了控制队列中数据包出队的速率,就需要精确计算单位时间内出队的数据包数或数据包总大小,而这通常是很复杂的。为了进行简化,现在一般都使用另一种机制:系统以一定的速率产生令牌,每个数据包(或一个字节)对应一个令牌,只有当令牌充足的时候数据包才能出队。
打个比方来说,在游乐园里有很多游客在排队等待乘坐过山车。让我们假设过山车按照固定的时间到来。游客必须等待一列过山车到来后才能乘坐。在这里,过山车上的位置就相当于令牌,而游客就相等于数据包。这就是网络速率限制,或者称为shaping。在单位时间内,只能有固定数量的游客乘上过山车(出队)。
继续这个过山车的比喻,假设某个时刻没有游客排队,而车站里有很多车子,这时候来了一大波游客,那么这些游客的大多数人(甚至是全部)都能立刻乘上过山车(因为此时车站里有很多空车)。车站里所能停放的过山车数量就是令牌桶中“桶”的大小。桶中积攒起来的令牌能在突然出现大量数据包时全部使用出去。
让我们完成这个比喻。游乐园里的过山车以恒定速率到来,如果没有游客排队的话,就停放在等待区里,直到等待区里停满了车子。在令牌桶模型中,令牌以恒定的速率填充到桶中,直到桶满了为止。使用令牌桶模型进行流量整形能应付诸如HTTP应用之类会产生突发数据传输的情形。
TBF 排队规则是一个经典的流量整形实现(在TBF小节中有一张图表能帮助读者理解令牌桶)。TBF以rate的速率产生令牌,并在桶中有令牌的时候才发送数据包。
当队列中没有数据包的时候,就暂时不需要使用令牌,这时令牌就会在桶中积累起来。如果桶的容量是无限制的,那就会失去流量整形的意义,因此,桶的容量必须是有限的。因为在桶中积累了一定数量的令牌,此时若队列中突然出现大量数据包需要出队,我们也有足够的令牌保证数据包能够顺畅出队。
这就是说,一个装满的令牌桶能在一定时间内应付任何类型的流量。比较恒定的网络流量适合使用较小的令牌桶。经常有突发数据传输的网络则比较适合使用大的令牌桶,除非流量整形的目的是为了限制突发数据传输。
概括来说,系统会以恒定的速率产生令牌,直到令牌桶满了为止。令牌桶能够在保证较长一段时间内网络流量在限制值以下,又能处理大速率的突发数据传输。
令牌桶模型也被应用于TBF(一种classless qdiscs)和HTB(一种classful qdiscs)中。在tcng语言中,two- and three-color meters也是一种令牌桶模型的应用。
2.8. 数据包和帧
一块数据被称为什么取决于它位于哪一层网络栈中。虽然这里写出了数据包和帧两个名词,但在整个文档中将不会刻意区分这两个词在技术上的区别(这通常是错误的做法!)。
帧通常被用于描述位于第二层(数据链路层)的数据块。以太网接口、PPP接口和T1接口都把位于第二层的数据块称为帧。在这种情况下,帧就是流量控制所要操作的对象。
在其他情况下,位于第三层(网络层)的数据块被称为数据包。虽然不太精确,但本文将会使用数据包这一名词进行说明。
[2] 除了先进先出队列,还有一种队列是优先级队列。优先级队列可以让后到的数据包先被发送出去。
[3] 简单来说,流量控制系统对高层应用来说就是一个接收数据包的层而已。
3. 流量控制中的概念
3.1. 整形
整形就是流量控制,把数据包的发送速率控制在一个固定的水平以下。
整形会控制队列中数据包的发送速率,使其保持在一个固定的值以下。这是最常用的流量控制手段。由于整形通过延迟数据包的发送来控制数据包发送速率,故整形机制是非工作保存的。“非工作保存”可以理解为:系统必须进行一些操作来延迟数据包的发送。
反过来说,一种非工作保存的队列是可以进行流量整形的,而工作保存的队列(参考 PRIO)不能进行流量整形,因为工作保存队列无法延迟发送数据包。
流量整形能将网络流量限制在一个固定的速率下,通常以位/秒或字节/秒作为衡量单位。但这也有副作用,那就是突发的数据传输也会被限制在一个较低的速率下。 [4]. 流量整形的好处之一是可以控制数据包的延迟时间。在流量整形中,通常会使用令牌桶机制来实现整形。 查看 第 2.7 节 “令牌桶” 以了解更多有关令牌桶的信息.
3.2. 调度
一个调度器会对将要发送的数据包顺序进行排列或重排。
对队列中对数据包顺序进行排列或重排就叫做调度。最常见的调度器是FIFO(先入先出队列)。由于数据包必须按顺序出队,因此队列实际上就是一个调度器。
对于不同的网络环境,我们可以使用不同的调度器。一个公平队列算法(参考SFQ)能防止一个客户端或一个数据流占用过多的带宽。一个循环算法(参考WRR)可以让各个客户端或数据流都有平等的使用网络的机会。还有一些更复杂的算法可用于防止骨干网流量过载,或者是对一些常见算法的改进。
3.3. 分类
分类器能把不同类型的网络流量划分到不同的队列中去。
把数据包按照不同类型进行划分叫做分类。通常我们只对上行流量进行分类。在路由器接收、路由并转发一个数据包的时候,网络设备可以以几种不同的方式给数据包进行分类。其中一种方式是标记数据包。标记数据包的操作可以在一个网络中由管理员进行设置,也有可能在数据包经过每一跳时发生。
Linux允许数据包通过一系列的流量控制结构,期间允许用户使用决策器对数据包进行分类(参考第 4.3 节 “过滤器”和第 4.5 节 “决策器”)。
3.4. 策略
决策器能计算并限制某个特定队列的流量。
在流量控制中使用决策器来控制流量是非常简单的。决策器通常会应用于网络边界上,某个节点使用的流量不会超过分配给它的流量。当网络流量在预设值以下时,决策器什么都不会做。但当网络流量超过预设值时,决策器就开始发挥作用,它能将流量速率控制在一个固定的水平之下。最不近人情的操作是即使在数据包能够继续分类的情况下依旧直接将其丢弃。
决策器只会区别对待两种情况,分别是入队数据包速率高于或低于预定速率。当入队速率低于预设值时,决策器就会允许数据包入队。当入队速率高于预设值时,决策器就执行其他操作(丢包或重新分类)。虽然决策器内部使用令牌桶来计算速率,但它并不像shaping那样会延迟数据包的发送。
3.5. 丢弃
丢弃一个数据包,一个数据流或一个分类下的数据包,都可以叫做丢弃。
丢弃一个数据包就叫做丢包。
3.6. 标记
标记是一种对数据包进行一些修改的操作。
![]()
注意
这里说的标记不是fwmark。iptables,$ipt-mark;,ipchains以及--mark都只修改数据包的元数据,而不修改数据包本身。
流量控制中的标记操作会给数据包加上一个DSCP,接下来在由一个管理员控制的一个网络下的其他路由器上将会使用这个标记。
[4] 在后面的内容中,我们会看到如何使用HTB来消除这种副作用。
4. Linux流量控制中的组件
表 1. 流量控制的概念与Linux中流量控制组件的对应关系
流量控制概念
Linux流量控制组件
schedulingqdisc就是一个调度器。调度器有比较简单的FIFO,也有比较复杂的如HTB之类的调度器。
classifyingfilter会附着在classifier上进行分类工作。 严格来说,分类器必须依靠过滤器才能正常工作。
policingpolicer可以看成是filter的一个子功能。
dropping
将filter和policer配合使用,并将policer的动作设为“丢包”,就可以丢弃指定的数据流。
markingdsmark qdisc用于给数据包打上标记。
4.1. qdisc
简单来说,qdisc其实就是一个调度器(第 3.2 节 “调度”)。每个网络接口都会有一个调度器,默认的调度器是FIFO。qdiscs会根据调度器的规则重新排列数据包进入队列的顺序。
qdisc 是 Linux 流量控制系统的核心。qdisc 也被称为排队规则。
classful qdiscs 可以包含多个 class,数据包根据 filter 的设置被分发到特定的 classful qdiscs 上。分类排队规则可以没有子类,但这样做通常会导致系统资源被白白浪费。
classless qdiscs 是没有分类的。由于非分类的排队规则没有子对象,所以 classifying 中也没有针对其的操作。因此,非分类的排队规则无法和过滤器相关联。
许多人常常弄不清楚 root qdisc 和 ingress qdisc 有何区别。这两者都不是真正的排队规则,他们只是一个供我们建立自己的流量控制结构的地方。出站数据包规则可以附加到 egress 上,而入站数据包可以附加到 ingress 上。
egress 和 ingress 存在于每一个网络接口上,在流量控制中最常用的是 egress,也就是我们所熟知的 root qdisc。root qdisc 能与任何类型的排队规则相关联,形成流量控制结构。每一个出站的数据包都要经过 egress,或者说都要经过 root qdisc 排队规则。
网络接口上收到的数据包都将经过 ingress qdisc。ingress qdisc 下无法创建任何分类,且只能与一个 filter 相关联。一般情况下,ingress qdisc 仅仅被当成是一个用于附加 policer 来控制入站流量的对象。
简而言之,egress 要比 ingress 更强大,更像是一个真正的排队规则。ingress 只能和决策器配合使用。本文也将重点介绍 root qdisc,除非特别说明,否则所有的操作都是默认针对 egress 进行的。
4.2. 分类
类仅存在于可分类的 qdisc 之下(如 HTB CBQ 等)。理论上,类能无限扩展,一个类可以仅包含一个排队规则,也可以包含多个各自排队规则的子类。 [5]. 一个类之下可以包含多个分类的排队规则。这就给 Linux 流量控制系统予以了极大的可扩展性和灵活性。
每一个类都有一个数字编号,filter 将根据这个编号与指定的类相关联。对数据包进行重分类或丢弃操作时也需要用这个数字编号来指定相应的分类器对象。
排队规则上的最末尾的分类成为叶子分类。叶子分类默认包含一个 FIFO 排队规则,且不会包含任何子分类。任何包含子分类的分类都不是叶子分类。
4.3. 过滤器
过滤器是 Linux 流量控制系统中最复杂的对象,它是连接各个流量控制核心组件的纽带。过滤器最简单和最常见的用法就是对数据包进行分类。Linux允许用户使用一个或多个过滤器将出站数据包分类并送到不同的出站队列上(参考第 3.3 节 “分类”)。
- 一个过滤器必须有一个
classifier。 - 一个过滤器可以有一个
policer。
过滤器能与 qdisc 相关联,也可以和 class 相关联。所有的出站数据包首先会通过 root qdisc,接着被与 root qdisc 关联的过滤器进行分类,进入子分类,并被子分类下的过滤器继续进行分类。
4.4. 分类器
过滤器可以使用 tc 命令来进行操作,根据实际需求可以选择使用不同的分类器。最常用的分类器是 u32 分类器,它可以根据数据包中的属性对数据包进行分类。
分类器可以根据数据包的元数据对数据包进行分类,识别不同类型的数据包。在 Linux 流量控制中,分类器的使用是最基本的东西。
4.5. 决策器
决策器只能配合 filter 使用。决策器只有两种操作,当流量高于用户指定值时执行一种操作,反之执行另一种操作。灵活使用决策器可以模拟出三色计(three-color meter)。请参考第 10 节 “图表”。
policing 和 shaping 都是 Linux 流量控制中的基本组件,两者都可以对带宽进行限制。但不同的是, shaping 能保存并延迟发送数据包,而 policing 只会直接丢弃数据包。请参考 例 5 “tc filter”。
4.6. 丢包
丢包操作只能在 policer 中使用。任何已经与 filter 关联的 policer 都可以使用丢包操作。
![]()
注意
在 Linux 流量控制系统中,想要丢弃数据包只能依靠决策器;。决策器可以把进入队列的数据包流速限定在一个指定值之下。另外,它也可以配合分类器,丢弃特定类型的数据包。 [6].
然而,丢包也会造成副作用。比如, a packet will be dropped if the scheduler employed uses this method to control flows as the GRED does.
另外,当网络流量很大时,整形器或调度器可能会用光分配给它们的内存,这时候整形器和调度器也会开始丢弃数据包。
4.7. 句柄
每个 class 和分类的 qdisc (参考 第 7 节 “分类排队规则(分类 qdisc)”)都需要一个唯一的标识符。标识符就是句柄。标识符由一个主编号和一个子编号组成,编号必须是数字。用户可以自由指定编号,但必须遵守以下规则:[7]
分类器和排队规则句柄编号规则
主编号- 这个编号对内核来说没有意义。用户可以随意指定一个数字。但是,在流量控制结构中,一个对象下所有子对象的主编号必须相同。另外,按照惯例,
rootqdisc 的主编号通常应指定为1。 子编号- 排队规则的子编号必须为0,而分类器的子编号必须是非0值。一个对象下的所有分类器必须有相同的子编号。
特别地,ingress qdisc 的编号总是 ffff:0。
The handle is used as the target in classid and 在使用 tc filter 时,句柄将会作为 classid 和 flowid 的参数值,以指定操作对象。句柄仅供用户使用,内核会使用自己的一套编号来管理流量控制组件对象。
[5] 一个排队规则只能包含与其类型相同的类。举例来说,HTB 排队规则只能包含 HTB 分类,CBQ 排队规则不能将 HTB 分类作为自己的类。
[6] 想要实现这种功能,你需要一个 filter 和一个 classifier,使用分类器匹配特定类型的数据包,最后关联上一个 policer,并将决策器的操作指定为“丢包”,就像下面这样:police rate 1bps burst 1 action drop/drop。
[7] 我不知道编号数字的范围是多大,但我估计其范围应该是一个无符号32位整数(编号以十六进制表示)。
5. 软件和工具
5.1. 内核版本要求
大多数发行版的内核都带有 Linux 流量控制系统(即 QoS ),一些发行版将其编译为内核模块,令一些发行版则是直接将其静态编译到内核内。用户自己编译或一些自定义的内核可能没有包含流量控制模块。若要内核支持流量控制,需要在编译内核的时候选择下文列出的编译选项。
建议没有内核编译经验的用户先阅读 Kernel HOWTO。对于有经验的用户,在对流量控制系统有一定了解的情况下,可以根据自己的需求自行判断以下列出的选项哪些是自己所需要的。
例 1. 内核编译选项 [8]
# # QoS and/or fair queueing # 服务质量和公平队列 # 译注:下面的选项中的缩写的意义如下: # SCH,SCHED:调度 # CLS:分类器 # CBQ:类基队列 # HTB:分层令牌桶 # CSZ:Clark-Shenker-Zhang 调度算法,这是一种比较复杂的调度算法,以这三位开发者的名字命名。 # 个人用户一般用不到,本文也没有详细介绍 # PRIO:优先级队列 # RED:早期随机丢包 # SFQ:随机公平队列 # TBF:令牌桶 CONFIG_NET_SCHED=y CONFIG_NET_SCH_CBQ=m CONFIG_NET_SCH_HTB=m CONFIG_NET_SCH_CSZ=m CONFIG_NET_SCH_PRIO=m CONFIG_NET_SCH_RED=m CONFIG_NET_SCH_SFQ=m CONFIG_NET_SCH_TEQL=m CONFIG_NET_SCH_TBF=m CONFIG_NET_SCH_GRED=m CONFIG_NET_SCH_DSMARK=m CONFIG_NET_SCH_INGRESS=m CONFIG_NET_QOS=y CONFIG_NET_ESTIMATOR=y CONFIG_NET_CLS=y CONFIG_NET_CLS_TCINDEX=m CONFIG_NET_CLS_ROUTE4=m CONFIG_NET_CLS_ROUTE=y CONFIG_NET_CLS_FW=m CONFIG_NET_CLS_U32=m CONFIG_NET_CLS_RSVP=m CONFIG_NET_CLS_RSVP6=m CONFIG_NET_CLS_POLICE=y
只要开启了以上选项,内核就能支持本文描述的绝大部分功能。在使用某项功能之前,用户可能需要使用modprobe module 来开启相应功能。最后再次说明,看不懂本段内容的用户请先阅读 Kernel HOWTO 或有关内核编译的相关文档。
5.2. iproute2 工具 (tc)
iproute2 是一系列命令行工具,用于调整服务器的IP网络设定。本工具的使用文档请参考 iproute2 documentation,更详细的使用说明请参考 linux-ip.net。在 iproute2 工具集中,tc 是唯一一个用于流量控制的命令。本文档不会涉及 iproute2 工具集中除 tc 以外的命令。
由于 tc 在添加、修改和删除流量控制结构时直接和内核进行交互,所以编译 tc 必须先安装所有的 你想使用的 qdisc。特别地, HTB 在 iproute2 上游源码中还没有被支持。更多信息请参考 第 7.1 节 “HTB, 分层令牌桶”。
由于 tc 要直接修改内核中的流量控制结构,所以 tc 的语法通常是比较晦涩难懂的。The utility takes as its first non-option argument one of three Linux traffic control components, qdisc, class or filter.
例 2. tc 命令用法
[root@leander]#tc用法: tc [ 选项 ] 对象 { 命令 | help } 其中 对象 := { qdisc | class | filter } 选项 := { -s[tatistics] | -d[etails] | -r[aw] }
每个对象都包含更多的选项,本文无法涉及所有的选项。这里给出的例子只包括了最常见的用法。更多例子请参考 LARTC HOWTO。如果想了解得更透彻,可以考虑阅读 iproute2 的源码。
例 3. tc qdisc
[root@leander]#tc qdisc add \增加一个排队规则。这里的动词也可以是 del。>dev eth0 \指定一个设备,排队规则将会与这个设备相关联>root \在 tc 命令中,这相当于 “egress”。在这里必 \ 须使用 root。ingressqdisc 也可以关联到这个 \ 设备上,只是其功能要少一些。>handle 1:0 \handle可以由用户指定,格式是主编号:子编号.\ 排队规则的从必须是零(0)。编号可以简写为 “ \ 1:”的形式,这时子编号默认设为0.>htb\ 这是要关联的排队规则,在这个例子中,排队规 \ 则的类型是 HTB。排队规则(qdisc)的参数跟 \ 在后面。在这个例子中,我们没有指定任何排队 \ 规则的参数。
上面的例子是 tc 最简单的使用。下面将会给出一个例子,使用 tc 将一个类添加到一个已经存在的父类上。
例 4. tc class
[root@leander]#tc class add \添加一个分类,这里的动词也可以是del。>dev eth0 \指定一个设备,分类将会与这个设备相关联。>parent 1:1 \指定父类的handle,我们添加的分类将会成为这 \ 个父类的子类。>classid 1:6 \这是一个唯一的handle,(主编号:子编号)。子编 \ 号必须是非零值。>htb \所有的 classful qdiscs 都要求其子类拥有和它相 \ 同的类型。也就是说,这里的 HTB 排队规则包含 \ 的子类必须是 HTB 的。>rate 256kbit \这里是分类器的参数。参数的意义请参考 \ 第 7.1 节 “HTB, 分层令牌桶”。>ceil 512kbit
例 5. tc filter
[root@leander]#tc filter add \增加一个过滤器。这里的动词也可以 \ 是del。>dev eth0 \指定一个设备,分类器将会与这个设 \ 备相关联。>parent 1:0 \指定一个对象的编号,过滤器将会与 \ 这个对象相关联。>protocol ip \这个参数是必需的,它的用处很明显 \ ,但是我不知道这个参数还有什么其 \ 他的作用。>prio 5 \prio参数指定了过滤器的优先级.\ pref是 prio 的同义词。>u32 \这是一个classifier,所有的 tc\ filter命令都必须包含这一项 。>match ip port 22 0xffff \这是分类器的参数。在这个例子中, \ 端口为22且带有服务标记的数据包( \ 交互型应用)将会被选中。>match ip tos 0x10 0xff \>flowid 1:6 \flowid参数指定了一个分类或排队规 \ 则的handle,被选中的数据包将会被 \ 发送到这个分类或排队规则上。>police \这是一个policer。在 tcfilter命 \ 令中,这一项是可选的。>rate 32000bps \当流量大于此速率时,决策器将会执 \ 行一个操作,反之执行另一个操作( \ 请参考 action parameter)。>burst 10240 \Theburstis an exact analog t \ oburstin HTB (burstis a \ buckets concept).>mpu 0 \最小决策单元。要统计所有的数据包 \ ,将mpu的值设为零(0)。>action drop/continue\action指定了决策器的操作。第一个 \ 词指定了当流量超过rate时的操作 \ ,第二个词指定了其他情况下的操作
正如上面例子里面的一样,即使是很简单的操作,tc 的命令也是十分复杂。其实,有一种工具可以简化这些工作,请看下一节 第 5.3 节 “tcng, 下一代tc”。
5.3. tcng, 下一代tc
FIXME; sing the praises of tcng. See also Traffic Control using tcng and HTB HOWTO and tcng documentation.
下一代tc(Traffic Control Next Generation)。 下一代tc提供强大的功能,让你不再为 tc 复杂的语法而头疼。
5.4. IMQ, 中间队列设备
FIXME; must discuss IMQ. See also Patrick McHardy’s website on IMQ. 待完善。可以参考 Patrick McHardy 网站上有关 IMQ 的内容。IMQ,中间队列设备(Intermediate Queuing device)。
[8] 此处列出的选项来源于 2.4.20 版本的内核源码。如果内核版本比 2.4.20 新,或者内核源码已经打上了补丁,选项的名字可能会和这里列出的有些不同。
6. 非分类排队规则(非分类 qdisc)
任何一个非分类排队规则都可以作为网络接口上的根对象,也可以作为分类排队规则的叶子对象。这里列出的非分类排队规则是 Linux 下最基本也是最重要的排队规则。
6.1. FIFO, 先入先出 (pfifo 和 bfifo)
![]()
注意
这个排队规则并不是 Linux 默认的排队规则。默认的排队规则是 pfifo_fast,其详细说明请参考第 6.2 节 “pfifo_fast, Linux 默认的排队规则”。
先入先出算法是 Linux 下网络设备上使用的最基本的包调度算法(默认是调度算法是 pfifo_fast)。先入先出算法既不会对网络流量进行整形操作,也不会重新排列数据包,它只会尽可能快地把数据包发按顺序发送出去。默认情况下,每一个新创建的分类器都将先入先出算法作为默认的排队规则。

使用先进先出算法的排队规则都有一个缓存,这是为了在数据包(或数据)无法及时发送出去时,暂时保存这些数据包(或数据)。Linux 有两种类型的先入先出 qdisc,一种是基于字节的,另一种是基于数据包的。无论使用哪种先入先出排队规则,都可以使用 limit 参数来指定缓存大小。当使用基于数据包的 pfifo 时,缓存大小的单位就是数据包个数;当使用基于字节的 bfifo 时,缓存大小的单位就是字节。
例 6. 使用 limit 参数为先进先出排队规则指定一个缓存大小
[root@leander]#cat bfifo.tcc/* * 在 eth0 设备上创建一个缓存大小为10千字节的先进先出排队规则 * */ dev eth0 { egress { fifo (limit 10kB ); } }[root@leander]#tcc < bfifo.tcc# ================================ Device eth0 ================================ tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0 tc qdisc add dev eth0 handle 2:0 parent 1:0 bfifo limit 10240[root@leander]#cat pfifo.tcc/* * 在 eth0 设备上创建一个缓存大小为30个数据包的先进先出排队规则 * */ dev eth0 { egress { fifo (limit 30p ); } }[root@leander]#tcc < pfifo.tcc# ================================ Device eth0 ================================ tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0 tc qdisc add dev eth0 handle 2:0 parent 1:0 pfifo limit 30
6.2. pfifo_fast, Linux 默认的排队规则
pfifo_fast 是 Linux 下所有网络接口默认的排队规则。pfifo_fast 源于 FIFO,它在 FIFO 的基础之上增加了三条具有不同优先级的通道,每一条通道都是一个先入先出队列。最高优先级的数据包(如交互型应用)应该通过具有最高优先级的0号通道。类似地,1号通道优先级低于0号通道而又高于2号通道,2号通道的优先级最低。系统会首先发送高优先级通道中的数据包,当高优先级通道中没有数据包后,才会发送更低优先级通道中的数据包。也就是说,只有当0号通道中没有数据包时,1号通道中的数据包才会被发送,当1号通道中的数据包被发送完且0号通道也没有数据包时,才会发送2号通道中的数据包。

pfifo_fast 没有为用户提供任何可以修改的参数。有关 priomap 和 ToS 位的详细信息,请参考 pfifo-fast section of the LARTC HOWTO。
6.3. SFQ, 随机公平队列
SFQ 会使用随机算法尽力让每一个 flows 都能公平地将自己的数据发送出去。SFQ 会使用一个散列函数来完成随机分配,根据散列函数的值将数据包分配到由它自己维护的一系列 FIFO 中,并循环发送这些 FIFO 中的数据,以此实现随机发送。由于一直使用固定的散列算法可能会造成不公平的情况,所以散列算法每隔一段固定的时间就会更改一次,用户可以修改 perturb 参数的值来控制这一时间间隔。

例 7. Creating an SFQ
[root@leander]#cat sfq.tcc/* * 在 eth0 设备上创建一个 SFQ 排队规则,每10秒更换一次散列算法 * */ dev eth0 { egress { sfq( perturb 10s ); } }[root@leander]#tcc < sfq.tcc# ================================ Device eth0 ================================ tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0 tc qdisc add dev eth0 handle 2:0 parent 1:0 sfq perturb 10
不幸的是,一些客户端(如 Kazaa,eMule 等)会从随机公平队列中获利,因为这写客户端通常会开启大量 TCP 会话,每一个会话就相当于一个 flows,这样,由 SFQ 自行在其内部维护的 FIFO 就会被这些 TCP 会话占领,导致其他数据包被不公平地对待。在通常情况下,SFQ 能很好地分配网络资源,但如果网络上存在类似这些令人抓狂的客户端或用户的话,整个网络就会变得非常不稳定。
有关 SFQ 的更多设定参数,请参考 第 6.4 节 “ESFQ, 扩展的随机公平队列”。
6.4. ESFQ, 扩展的随机公平队列
从概念上来说,虽然这个排队规则给了用户比 SFQ 更多的可设定参数,但是它和 SFQ 没有本质上的区别。这个排队规则让用户能够调整散列算法的细节,以便更好地分配网络资源,弥补 SFQ 的不足。
例 8. ESFQ 的用法
用法: ... esfq [ perturb 秒 ] [ quantum 字节 ] [ depth FLOWS ]
[ divisor 散列位 ] [ limit PKTS ] [ hash 散列类型]
Where:
散列类型 := { classic | src | dst }
待完善:需要补充更多内容,包括例子和实践。
6.5. GRED, 早期随机丢包
待完善:笔者没有使用过这种方法。需要补充例子和实践。
早期随机丢包通常只用在骨干路由器或核心网络上,一般用户很少用到。
6.6. TBF, 令牌桶
令牌桶排队规则是基于 tokens 和 buckets 这两个概念之上的。要对网络设备上的出站流量进行整形,使用令牌桶排队规则是个不错的解决方案,因为它只会减慢数据包发送速率而不会丢弃数据包。
当有足够的令牌时,数据包才能被发送出去,否则,数据包将被暂存起来延迟发送。通过这种方法延迟数据包的发送将会认为地增大数据包的来回时间。

例 9. 创建一个将网络流量速率整形为 256kbit/s 的 TBF
[root@leander]#cat tbf.tcc/* * 在 eth0 设备上创建一个令牌桶排队规则,将流量整形为 256kbit/s * */ dev eth0 { egress { tbf( rate 256 kbps, burst 20 kB, limit 20 kB, mtu 1514 B ); } }[root@leander]#tcc < tbf.tcc# ================================ Device eth0 ================================ tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0 tc qdisc add dev eth0 handle 2:0 parent 1:0 tbf burst 20480 limit 20480 mtu 1514 rate 32000bps
7. 分类排队规则(分类 qdisc)
分类排队规则赋予了 Linux 流量控制系统极大灵活性。记住,分类排队规则允许与过滤器相关联,并将数据包分配到子分类和子排队规则上去。
与 root qdisc 或父类相关联的分类器有好几种不同的描述方法。与 root qdisc 相关联的分类可以叫做根分类,也可以叫做内部分类。任何不包含子分类的分类通常被称作叶子分类。在本文中,我们将使用类似树型结构的描述方法,同时也会使用类似家庭成员代词(如孙子节点、兄弟节点)进行描述。
7.1. HTB, 分层令牌桶
HTB 基于令牌和桶的概念,并按照基于对象的方法,同时配合 filter,实现了一个复杂而又精细的流量控制方法。利用其提供的 borrowing model 机制,用户能够构造出十分强大而有效的流量控制结构。HTB 最简单,同时也是最直接的使用,就是 shaping。
如果已经充分了解了 tokens 和 buckets 的概念,或者是已经能够熟练使用 TBF,那么掌握 HTB 的使用方法也是水到渠成的事了。HTB 允许用户创建一系列具有不同参数的令牌桶,并按需要将这些令牌桶归类,同时配合使用classifying,就能够实现较细粒度的流量控制。
下面是 tc 给出的 HTB 的用法。在编写 tcng 配置时,同样可以使用这些参数。
例 10. tc 中 HTB 的用法
用法: ... qdisc add ... htb [default N] [r2q N]
default 当数据包没有被分类时,将通过这里指定的分类发送 {0}
r2q DRR quantums are computed as rate in Bps/r2q {10}
debug string of 16 numbers each 0-3 {0}
... class add ... htb rate R1 burst B1 [prio P] [slot S] [pslot PS]
[ceil R2] [cburst B2] [mtu MTU] [quantum Q]
rate rate allocated to this class (class can still borrow)
burst max bytes burst which can be accumulated during idle period {computed}
ceil 指定分类的最高速率(不包含租借流量) {rate}
cburst burst but for ceil {computed}
mtu max packet size we create rate map for {1600}
prio 叶子优先级,数字越小优先级越高 {0}
quantum 叶子节点一次能够提供的字节数 {use r2q}
TC HTB version 3.3
7.1.1. 软件需求
和其他流量控制组件不一样,HTB 是一个较新的组件,你的内核可能不支持它。要让内核支持 HTB,必须使用 2.4.20 或更新版本的内核。就版本的内核需要打上补丁才能支持 HTB。要在用户空间上使用 HTB,请参考 HTB 中有关iproute2 的 tc 补丁的内容。
7.1.2. 整形
HTB 最常用的功能就是整形,也就是把出站速率限制在一个固定值之下。
所有的整形操作都在叶子分类上进行。内部分类和根分类都不会进行整形操作,它们仅在 borrowing model 中用于控制出借令牌应该如何分配。
7.1.3. 租借模型
HTB 的一个重要特性就是租借模型。当子分类的流量超过了 rate 时,它们就会向父分类借用令牌,直到子分类借到的令牌数量满足能让其达到 ceil 指定的速度为止,与此同时,它会暂缓发送数据包,直到有了足够多的令牌(token 或 ctoken)。由于 HTB 结构树中只有两种主要类型的节点(或者说是分类),下面以表格形式列出两种节点在不同情况下时会采取的动作。
表 2. HTB 中的节点在不同状态下的不同动作
节点类型
节点状态
HTB 内部状态
动作
叶子节点
< rateHTB_CAN_SEND
在令牌充足时叶子节点将会发送数据(不超过 burst 个数据包)
叶子节点
> rate, < ceilHTB_MAY_BORROW
叶子节点会试图向父节点借用令牌(tokens 或 ctokens)。如果父节点有足够的令牌,就会一次性借给子节点 quantum 的整倍数个令牌,接着叶子节点发送最多 cburst 个字节。
叶子节点
> ceilHTB_CANT_SEND
暂缓发送数据包,这将增大数据包延迟,使网络接口上的流量符合整形速率。
内部节点,根节点
< rateHTB_CAN_SEND
本节点将会出借令牌给子节点。
内部节点,根节点
> rate, < ceilHTB_MAY_BORROW
本节点试图将向父节点借用令牌(tokens 或 ctokens),并将借到的令牌按照 quantum 的整数倍出借给子节点。
内部节点,根节点
> ceilHTB_CANT_SEND
本节点不会向父节点借用令牌,也不会向子节点出借令牌。
下图绘出了借用令牌和归还令牌的流向。为了使租借模型正常运行,必须为每个分类指定明确的令牌数量,及其子分类可用的令牌数量。同样,子分类或叶子节点必须向其父对象归还借用的令牌,层层向上直到根分类。
当子节点向其父节点借用令牌时,不论父节点是否已经超过了自己的 rate,他都会向上一级节点请求借用令牌,直到借到了令牌,或者达到了根节点为止。所以,出借令牌的流向是从根到叶子,而归还令牌的流向是从叶子到根。

此图中有多个 HTB 根分类,每一个根分类都可以模拟成一条虚电路。
7.1.4. HTB 分类参数
default
所有 HTB qdisc 对象的默认值,这个参数是可选的。默认的 default 值为0,这意味着所有通过 root qdisc 的数据包将以设备的最大吞吐能力发送出去。
rate
设定整形流量速率的最小速度。这个值可以当作承诺信息速率(CIR,也可以当作叶子节点的最低带宽。
ceil
设定整形流量速率的最大速度。租借系统的设置将影响这个参数的实际作用。这个参数可以当作是“突发速率”。
burst
这是 rate 令牌桶的大小。 (参考 Tokens and buckets)。HTB 会在令牌(tokens)还没有到来的情况下提前发送 burst 个字节的数据。
cburst
这是 ceil 令牌桶的大小。HTB 会在令牌(ctokens)还没有到来的情况下提前发送 burst 个字节的数据。
quantum
这个参数在 HTB 的租借系统中很重要。通常,HTB 会自己计算合适的 quantum 值,而不需要用户手工指定。有人认为调整这个参数能在出借令牌和整形方面收到不少好处,但也有不少人持反对意见,because it is used both to split traffic between children classes over rate (but below ceil) and to transmit packets from these same classes.
r2q
r2q 可以由用户自行指定,HTB 会参考用户设定的值,为每个分类计算出一个更合适的 quantum
mtu
prio
7.1.5. Rules
下面是一些一般性的提示,这些提示是从 http://docum.org/ 和 LARTC mailing list 中选取出来的,可以给入门用户提供指导性的意见,尽可能地发挥 HTB 的效能。对于高级用户,则可以根据自己的实际需要调整 HTB 以获取最大效益。
- 在 HTB 中,只有叶子节点才会对流量进行整形。参考 第 7.1.2 节 “整形”。
- 因为在 HTB 只有叶子节点会对流量进行整形,所以一个分类下的所有叶子节点的
rate之和不应该超过这个分类的ceil。通常我们建议将分类的rate值设定为其所有子节点的rate之和,这样,分类随时都能有剩余的带宽(ceil–rate)分配给子节点。由于这个概念十分重要,所以才一而再再而三地强调:在 HTB 中只有叶子节点才会对流量进行整形,数据包只会在叶子节点中被暂存,任何中间节点都不会对流量进行整形,中间节点只在租借模型中起作用(参考 第 7.1.3 节 “租借模型”)。 quantum仅在当一个节点的速率大于rate而小于ceil时起作用。quantum的值应该至少设为和 MTU 一样大,或者比 MUT 更大。即使quantum设置值过小,但一有机会 HTB 就会立即发送一个数据包,这将导致 HTB 无法正确计算带宽消耗,也就无法正确地对流量进行整形 [9]。- 父节点每次借给子节点的令牌数都是
quantum的整数倍,因此,为了使网络反应更加迅速、粒度更细,quantum应该设置得尽可能小,而又不能小于 MTU。 - tokens 和 ctokens 仅仅在叶子节点上才有区别,因为非叶子节点只会将令牌借给它自己的子节点。
- HTB 的租用模型更精确的说法应该叫做“租借后使用机制”。
7.2. HFSC, 分层公平服务曲线
HFSC(Hierarchical Fair Service Curve,HFSC)能够将延迟敏感型流量和吞吐量敏感型流量区分对待,它会根据服务曲线定义在拥挤的线路上保证延迟敏感型数据包能够被及时发送,同时线路又保持有较大的吞吐量。有关 HFSC 的详细情况请参考 HFSC Scheduling with Linux 和 A Hierarchical Fair Service Curve Algorithm For Link-Sharing, Real-Time and Priority Services。
本节尚待日后完成。
7.3. PRIO, 优先级调度
PRIO 分类排队规则十分简单,当允许发送数据包时,PRIO 会首先检查第一个分类中有没有数据包,如果有就发送出去,如果没有数据包,就检查下一个分类,以此类推,直到检查完所有的分类。
本节尚待日后完成。
7.4. CBQ, 基于类的队列
基于类的队列(Class Based Queuing)是非常经典的排队算法。本节尚待日后完成。
[9] HTB 会使用 quantum 而非实际的数据包大小来计算流量,这就会导致流量消耗计算错误,且误差会迅速扩大。
8. 约定和一些常见场景
8.1. 一般性的提示
这里列出了一些例子,方便入门的读者更快地了解 Linux 流量控制系统。
无论用户使用 tcng 还是 tc 配置流量控制系统,流量控制的结构都是相同的。
- 实行流量整形的路由应该是整条链路上的瓶颈。一般情况下路由器都应该把整形流量限制为比线路带宽稍低一些,这样可以避免过量的数据包阻塞路由器,让路由器能够有效地工作。
- 理论上来说,流量控制系统只能对上行流量进行整形。 [10]. 因为下行流量是从网络上发送过来的,我们无法直接控制接收到的数据流量。虽然可以使用在 ingress 上使用决策器来控制入站流量,但本机和上级路由间的线路上的流量并不会因此减少。
- 每个网络接口都有必须有一个
qdisc。如果用户没有为网络接口指定qdisc,系统就会默认使用pfifo_fast作为网络接口的默认排队规则。 - 如果向网络接口上关联了一个 classful qdiscs,而又没有向这个排队规则上添加任何子分类,那只会白白浪费处理器时间。
- 新创建的分类默认包含一个 FIFO 排队规则。如果用户为分类指定了一个新的排队规则,那么用户指定的排队规则就会取代 FIFO。如果用户为分类指定了子类,那么 FIFO 就会自动被删除。
- 可以直接往
rootqdisc 上关联分类来模拟一条虚电路。 filter可以与分类器或 classful qdiscs 相关联。
8.2. 在已知带宽的线路上实施流量控制
如果线路的带宽是已知的,那么使用 HTB 是个不错的决定。因为用户可以把根节点的整形流量设置为线路的最大带宽。整个线路的流量可以一级一级细分到子分类去,用户可以灵活地指定各种不同的应用和流量可用的带宽。
8.3. 在带宽可变(或未知)的线路上实施流量控制
理论上来说,PRIO 是最适合用在带宽未知或带宽可变的线路上的,因为 PRIO 是一种工作保存(work-conserving)的排队规则,也就是说 PRIO 是不会对流量进行整形的。在这样一种带宽不稳定的线路上,PRIO 可以优先发送高优先级的数据包,然后再发送低优先级的数据包。
8.4. 基于数据流的流量控制
由于网络上存在多种多样的连接,使用 SFQ 能简单而有效地管理这些连接。SFQ 会将网络流量分为多个不同的数据流,然后随机并公平地发送这些数据流。如果网络上都是行为良好的用户和程序,那么使用 SFQ 会让用户觉得网络的状态和稳定性是很不错的。
的弱点在于当它面对非常规的网络应用时,其随机公平服务算法就会显得十分无力。有一些客户端(如 迅雷,eMule,eDonkey,Kazaa 等)会创建大量的网络会话,这些网络会话会占领所有的数据流,于是随机公平服务算法对这些客户端来说就成了优先服务算法,其它的应用将得不到公平的服务。SFQ 没办法对这种应用进行惩罚,所以在这种情况下,我们需要使用其它的排队规则。
8.5. 基于IP地址的流量控制
对于许多网络管理员来说,这是控制用户对网络的使用的最好办法。但遗憾的是,tc 没有提供简单的方法来对一大堆IP地址分别设置不同的流量控制参数,用户数越多,流量控制结构也就越复杂。
如果要控制 N 个 IP 地址的流量,就需要至少 N 个分类。
[10] 使用 中间队列设备(Intermediate Queuing Device,IMQ) 可以模拟出一个虚拟的向外发包的网络接口,并且可以对其实施流量控制。中间队列设备对内核来说就像是一个普通的网络接口,利用这一点,我们可以把入站流量转入中间队列设备,使入站流量成为中间队列设备的上行流量,这样就可以在中间队列设备上像控制出站流量一样对实际入站流量进行整形。
9. 用于流量控制和 QoS 设置的脚本
9.1. wondershaper
尚未完成,请参考 wondershaper.
9.2. ADSL 线路上的流量控制 (myshaper)
尚未完成,请参考 myshaper.
9.3. htb.init
尚未完成,请参考 htb.init.
9.4. tcng.init
尚未完成,请参考 tcng.init.
9.5. cbq.init
尚未完成,请参考 cbq.init.
10. 图表
10.1. 图例
下面是一张使用了 HTB 作为流量控制排队规则的结构图。点击这里可以查看大图。
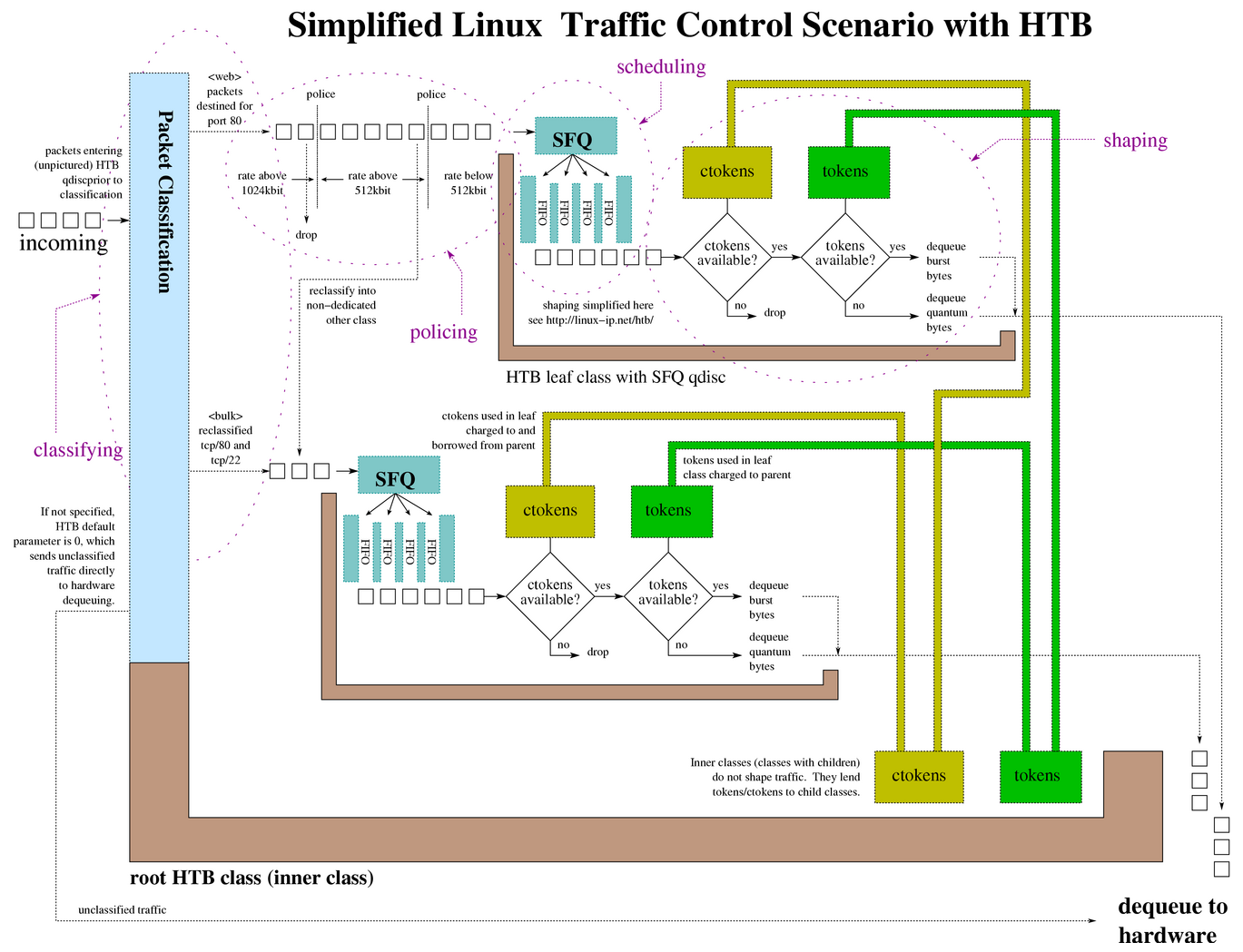{kind=link}
例 11. 一个使用 tcng 配置 HTB tcng 的例子
/*
*
* possible mock up of diagram shown at
* http://linux-ip.net/traffic-control/htb-class.png
*
*/
$m_web = trTCM (
cir 512 kbps, /* 承诺信息速率 */
cbs 10 kB, /* 突发承诺信息速率 */
pir 1024 kbps, /* 峰值信息速率 */
pbs 10 kB /* 突发峰值信息速率 */
) ;
dev eth0 {
egress {
class ( <$web> ) if tcp_dport == PORT_HTTP && __trTCM_green( $m_web );
class ( <$bulk> ) if tcp_dport == PORT_HTTP && __trTCM_yellow( $m_web );
drop if __trTCM_red( $m_web );
class ( <$bulk> ) if tcp_dport == PORT_SSH ;
htb () { /* root qdisc */
class ( rate 1544kbps, ceil 1544kbps ) { /* root class */
$web = class ( rate 512kbps, ceil 512kbps ) { sfq ; } ;
$bulk = class ( rate 512kbps, ceil 1544kbps ) { sfq ; } ;
}
}
}
}

11. 常用网站和资源
(译者注:这里列出的网站和手册都是英文的,所以就不翻译这个页面了。有兴趣的读者可以自己查看这些英文资料。)
This section identifies a number of links to documentation about traffic control and Linux traffic control software. Each link will be listed with a brief description of the content at that site.
- HTB site, HTB user guide and HTB theory (Martin “devik” Devera)Hierarchical Token Bucket, HTB, is a classful queuing discipline. Widely used and supported it is also fairly well documented in the user guide and at Stef Coene’s site (see below).
- General Quality of Service docs (Leonardo Balliache)There is a good deal of understandable and introductory documentation on his site, and in particular has some excellent overview material. See in particular, the detailed Linux QoS document among others.
- tcng (Traffic Control Next Generation) and tcng manual (Werner Almesberger)The tcng software includes a language and a set of tools for creating and testing traffic control structures. In addition to generating tc commands as output, it is also capable of providing output for non-Linux applications. A key piece of the tcng suite which is ignored in this documentation is the tcsim traffic control simulator.The user manual provided with the tcng software has been converted to HTML with latex2html. The distribution comes with the TeX documentation.
- iproute2 and iproute2 manual (Alexey Kuznetsov)This is a the source code for the iproute2 suite, which includes the essential tc binary. Note, that as of iproute2-2.4.7-now-ss020116-try.tar.gz, the package did not support HTB, so a patch available from the HTB site will be required.The manual documents the entire suite of tools, although the tc utility is not adequately documented here. The ambitious reader is recommended to the LARTC HOWTO after consuming this introduction.
- Documentation, graphs, scripts and guidelines to traffic control under Linux (Stef Coene)Stef Coene has been gathering statistics and test results, scripts and tips for the use of QoS under Linux. There are some particularly useful graphs and guidelines available for implementing traffic control at Stef’s site.
- LARTC HOWTO (bert hubert, et. al.)The Linux Advanced Routing and Traffic Control HOWTO is one of the key sources of data about the sophisticated techniques which are available for use under Linux. The Traffic Control Introduction HOWTO should provide the reader with enough background in the language and concepts of traffic control. The LARTC HOWTO is the next place the reader should look for general traffic control information.
- Guide to IP Networking with Linux (Martin A. Brown)Not directly related to traffic control, this site includes articles and general documentation on the behaviour of the Linux IP layer.
- Werner Almesberger’s PapersWerner Almesberger is one of the main developers and champions of traffic control under Linux (he’s also the author of tcng, above). One of the key documents describing the entire traffic control architecture of the Linux kernel is his Linux Traffic Control – Implementation Overview which is available in PDF or PS format.
- Linux DiffServ projectMercilessly snipped from the main page of the DiffServ site…
Differentiated Services (short: Diffserv) is an architecture for providing different types or levels of service for network traffic. One key characteristic of Diffserv is that flows are aggregated in the network, so that core routers only need to distinguish a comparably small number of aggregated flows, even if those flows contain thousands or millions of individual flows.
- 本文固定链接: http://www.wy182000.com/2013/04/17/linux-流量控制实施指南/
- 转载请注明: wy182000 于 Studio 发表